Smadzeņu attēlveidošana, mašīnmācīšanās var palīdzēt paredzēt garīgās slimības risku
Pētnieki apvieno smadzeņu attēlveidošanas datus un superdatorus, lai identificētu neiro attēlveidošanas datu modeļus, kas var palīdzēt prognozēt garīgo traucējumu, piemēram, depresijas vai demences, risku.
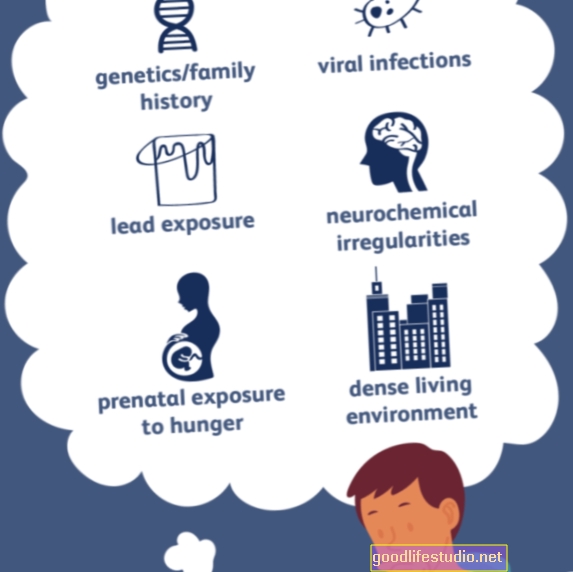
Depresija katru gadu skar vairāk nekā 15 miljonus pieaugušo amerikāņu jeb aptuveni 6,7 procentus ASV iedzīvotāju. Tas ir galvenais invaliditātes cēlonis cilvēkiem vecumā no 15 līdz 44 gadiem.
Dr David Schnyer, kognitīvais neirozinātnieks un psiholoģijas profesors Teksasas Universitātē Ostinā, sacīja, ka spēja prognozēt garīgo slimību risku nav vienkārša lieta.
Viņš izmanto superdatoru, lai apmācītu mašīnmācīšanās algoritmu, kas var identificēt simtiem pacientu kopīgās pazīmes, izmantojot magnētiskās rezonanses attēlveidošanas (MRI) smadzeņu skenēšanu, genomikas datus un citus būtiskus faktorus, lai precīzi prognozētu risku tiem, kam ir depresija un trauksme. .
Pētnieki jau sen ir pētījuši garīgos traucējumus, neiro attēlveidošanas datos pārbaudot smadzeņu funkcijas un struktūras saistību.
"Viena grūtība ar šo darbu ir tā, ka tas galvenokārt ir aprakstošs. Smadzeņu tīkli var šķist atšķirīgi starp divām grupām, taču tas mums neliecina par to, kādi modeļi faktiski paredz, kurā grupā jūs iekļūsit, ”sacīja Šnjē.
"Mēs meklējam diagnostikas pasākumus, kas prognozē tādus rezultātus kā neaizsargātība pret depresiju vai demenci."
2017. gadā Šnjērs, strādājot ar pētniekiem no dažādām universitātēm, pabeidza koncepcijas pierādījuma pētījuma analīzi, kurā tika izmantota mašīnmācīšanās pieeja, lai klasificētu personas ar smagiem depresijas traucējumiem ar aptuveni 75 procentu precizitāti.
Kopizmeklētāji ietvēra Dr. Pīters Klazens (Vašingtonas Universitātes Medicīnas skola), Kristofers Gonzaless (Kalifornijas Universitāte, Sandjego) un Kristofers Beeverss (Teksasas Universitāte, Ostina).
Mašīnmācība ir datorzinātņu apakšnozare, kas ietver tādu algoritmu izveidi, kas var “mācīties”, veidojot modeli no datu paraugu ievades, un pēc tam veikt neatkarīgas prognozes par jauniem datiem.
Pētnieki sniedza apmācības piemēru kopumu, no kuriem katrs tika atzīmēts kā veseliem indivīdiem, vai tiem, kuriem diagnosticēta depresija. Schnyer un viņa komanda savos datos iezīmēja nozīmīgas funkcijas, un šie piemēri tika izmantoti sistēmas apmācībai.
Pēc tam dators skenēja datus, atrada smalkus savienojumus starp atšķirīgām daļām un izveidoja modeli, kas piešķir jaunus piemērus vienai vai otrai kategorijai.
Pētījumā Šnjē analizēja smadzeņu datus no 52 ārstēšanu meklējošiem dalībniekiem ar depresiju un 45 smagiem kontroles dalībniekiem. Lai salīdzinātu grupas, viņi salīdzināja depresīvu dalībnieku apakškopu ar veseliem indivīdiem, pamatojoties uz vecumu un dzimumu, palielinot izlases lielumu līdz 50.
Dalībnieki saņēma difūzijas tenzora attēlveidošanas (DTI) MRI skenēšanu, kas iezīmē ūdens molekulas, lai noteiktu, cik lielā mērā šīs molekulas laika gaitā mikroskopiski izkliedējas smadzenēs.
Pētnieki salīdzināja iegūtos mērījumus starp abām grupām un atrada statistiski nozīmīgas atšķirības. Pēc tam viņi samazināja iesaistītos datus līdz apakškopai, kas bija visatbilstošākā klasifikācijai, un veica klasifikāciju un prognozēšanu, izmantojot mašīnmācīšanās pieeju.
"Mēs barojam veselus smadzeņu datus vai apakškopu un prognozējam slimību klasifikāciju vai jebkuru iespējamo uzvedības mēru, piemēram, negatīvas informācijas neobjektivitātes mērus," viņš saka.
Pētījums atklāja, ka smadzeņu dati var precīzi klasificēt nomāktus vai neaizsargātus indivīdus, salīdzinot ar veselīgu kontroli. Tas arī parādīja, ka prognozējošā informācija tiek izplatīta smadzeņu tīklos, nevis ir ļoti lokalizēta.
"Mēs ne tikai uzzinājām, ka, izmantojot DTI datus, mēs varam klasificēt nomāktus cilvēkus bez depresijas, bet arī kaut ko uzzinām par to, kā depresija tiek attēlota smadzenēs," sacīja psiholoģijas profesors un Garīgās veselības institūta direktors Beevers. Pētījumi Teksasas universitātē, Ostinā.
"Tā vietā, lai mēģinātu atrast apgabalu, kas ir nomākts depresijā, mēs uzzinām, ka izmaiņas vairākos tīklos veicina depresijas klasifikāciju."
Problēmas mērogs un sarežģītība prasa mašīnmācīšanās pieeju. Katru smadzeni pārstāv aptuveni 175 000 vokseļu, un, pārbaudot skenējumus, praktiski nav iespējams noteikt sarežģītas attiecības starp tik lielu komponentu skaitu.
Šī iemesla dēļ komanda izmanto mašīnmācīšanos, lai automatizētu atklāšanas procesu.
"Šis ir nākotnes vilnis," saka Šnjē."Konferencē mēs redzam arvien vairāk rakstu un prezentāciju par mašīnmācīšanās lietošanu, lai atrisinātu sarežģītas neirozinātnes problēmas."
Rezultāti ir daudzsološi, bet vēl nav pietiekami skaidri, lai tos varētu izmantot kā klīnisko metriku. Tomēr Schnyer uzskata, ka, pievienojot vairāk datu, kas saistīti ne tikai ar MRI skenēšanu, bet arī ar genomiku un citiem klasifikatoriem, sistēma var paveikt daudz labāk.
“Viens no mašīnmācīšanās ieguvumiem, salīdzinot ar tradicionālākām pieejām, ir tas, ka mašīnmācībai vajadzētu palielināt varbūtību, ka tas, ko mēs novērojam mūsu pētījumā, tiks piemērots jaunām un neatkarīgām datu kopām. Tas ir, tam vajadzētu vispārināt jauniem datiem, ”sacīja Beevers.
"Šis ir kritisks jautājums, kuru mēs patiešām priecājamies pārbaudīt turpmākajos pētījumos."
Avots: Teksasas Universitāte Ostinā, Teksasas Uzlabotais skaitļošanas centrs